众所周知,机器学习尤其是现在的深度学习,大量的工作都集中在调参上。一个模型能否很好的解决问题,调参占了很大的比重。而学习率又是模型众多超参数中最重要和最容易调节的一个。
1.什么是学习率
目前深度学习优化的基本思想是梯度下降法,已经有很多优秀的且模块化的梯度下降算法可以直接使用,比如最常用的SGD、Adam和RMSProp等,所有这些算法都要求使用者设定学习率,因为每个特殊的问题都有一个不同的最优学习率,必须根据实际情况来调节。
学习率代表了权重参数在逆梯度方向上调节的步长。学习率越小则模型效果越好,但是会带来极慢的速度并且会陷入局部最优。所以我们需要增大学习率,但是学习率过大又会导致函数无法收敛,或者跳出最优点,是的模型训练效果变得更差。因此选取一个合适的学习率是训练深度学习模型的第一步。
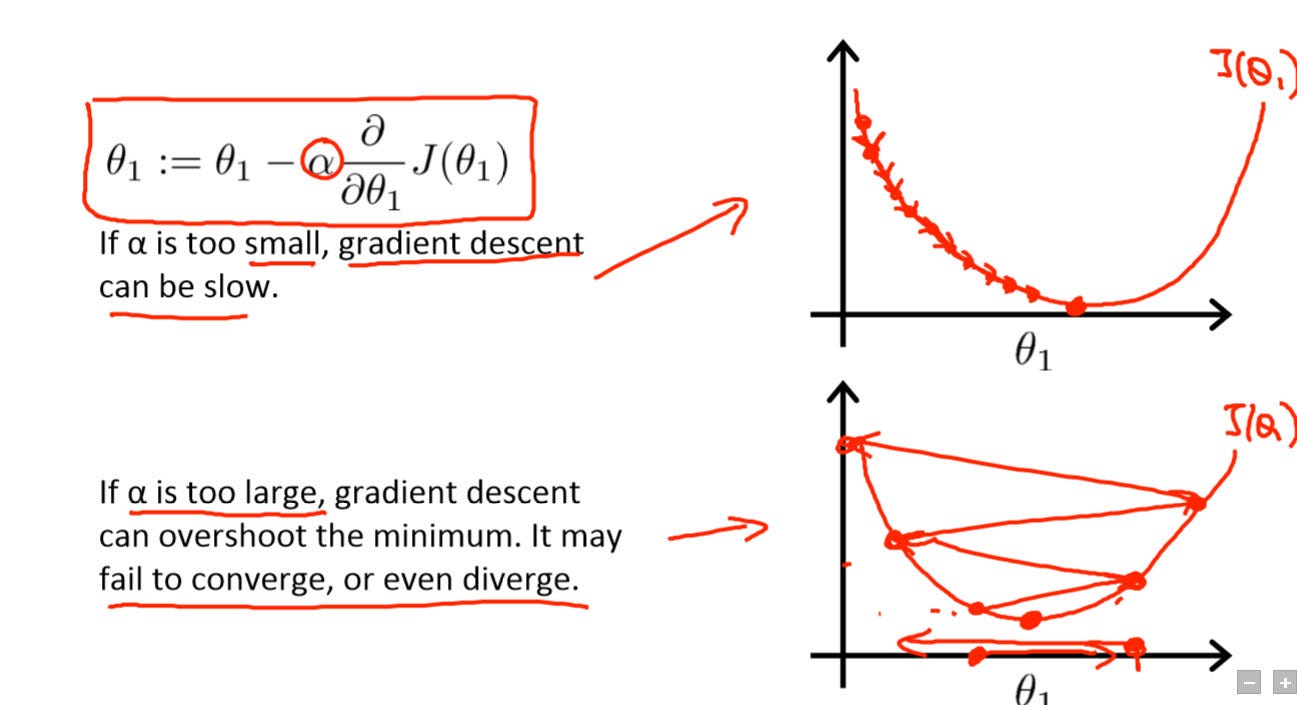
吴恩达深度学习课程中的学习率介绍
我们需要知道的是开始的学习率是较大的,因为初始化的权重离最优值较远。随着训练的进行,学习率是一个逐渐减小的状态。
2.如何选择最优的学习率
首先想到的就是一个笨方法,不断的测试不同数量级的学习率,如0.1、0.01等,每次减少或者增大一个到两个数量级。当学习率较大的时候,loss值不会减少。逐渐降低学习率,你会发现loss在开始的几个迭代开始下降,那这个学习率将是你能设置的上限,一般情况下会降低一到两个数量级来使用,因为训练的越多,权重的更新需求更细微。
那么怎样才能更用一个更聪明的方法来选择初始学习率,文章 “Cyclical Learning Rates for Training Neural Networks” 介绍了一种不错的方法:从0开始,每经过一个迭代就增加学习率。记录每个迭代的loss。
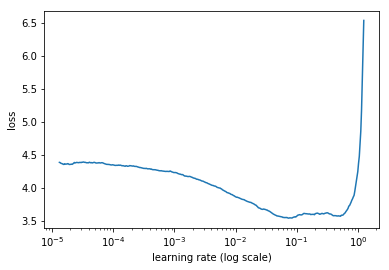
会得到上图的曲线,然后我们选择下降最快的一个区间,可以看到该图是0.01左右。
另一种方法是计算损失函数关于迭代次数的偏导数。然后以学习率为横轴,变化率为纵轴画图。
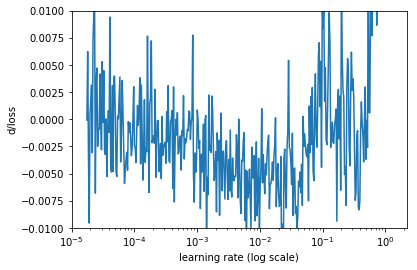
用简单移动平均来平滑一下,得到下图。
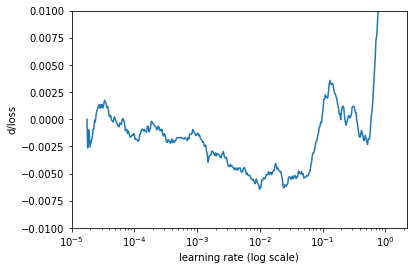
寻找最小值所在点,即0.01附近。
实现
感谢Jeremy Howard团队开发的pytorch工具包-fast.ai
理论上使用两行代码即可完成。使用的是第一种方法。(没有说明文档,不知道怎么用,日后完善)
learn.lr_find()
learn.sched.plot_lr()