注意力模型是近年来在序列处理领域新提出的机器学习方法,在语言翻译等领域取得了不错的效果。要想了解注意力模型,那么必须对现在的机器学习各领域有一定的了解,而且要了解encoder-decoder基本思想。
首先可以大致的概括下目前的机器学习尤其是深度学习的各个领域。图像方面,CNN当之无愧是绝对的主力,并且在各大公司的研究下仍然在发力。NLP(自然语言处理)方面,RNN型的网络仍然占多数,但是自从Facebook用CNN搭建的翻译模型超越谷歌的Seq2Seq以后,CNN已经开始蚕食RNN的领域。序列数据的处理不再是RNN类网络一家独大。
Attention-Model是Seq2Seq的一种,所谓的sequence就是指序列数据,序列数据处理一般有Seq2Label模型,如心电图分类、情感分析等。和Seq2Seq模型,如语言翻译和序列预测。
Encoder-Decoder
Attention-model是在编码-解码模型的基础上改进而来,所以在了解Attention-model前需要了解Encoder-Decoder的基本原理。
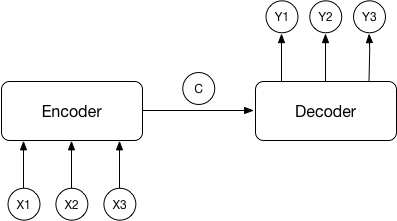
由上图可以清楚的看出,该结构由两部分组成,前面是由编码器处理输入信号,最后输出一个包含着序列信息的vector。解码器的输入是自身的input然后加上前面编码器输出的编码信息。
编码器和解码器的网络可以选择任意的结构,但是在NLP中选择RNN类网络的居多,如常用的LSTM和GRU等。
以语言翻译为例,前面编码器的输入是想要翻译的语言序列。经过编码器后产生一个代表着输入语句的语义编码C,然后解码器使用语义编码C、编码器的输出和一个起始符作为输入,共同完成解码工作。
我们可以看出该结构有一个明显的短板,即语义编码C是固定长度的。如果前面的序列比较长,那么语义编码C中包含的信息大部分都是关于序列后段的,前段的信息很可能已经被替换掉或者覆盖掉。因此序列越长这个问题就会越明显。
Attention-model
为了克服普通的Encoder-Decoder结构的缺陷,一种新的模型被提出。其主要思想是选择编码过程中重要的部分来作为编码的输入。根据量化的思想,主要做法就是对编码阶段的每个输出增加一个权重(用softmax获得),而且这个权重是根据编码过程中的隐含状态计算得到的,这样每一个序列都有一个不同的语义编码,由此决定序列中每一个部分的重要性。这样就可以很好的避免普通Encoder-Decoder模型的短板。
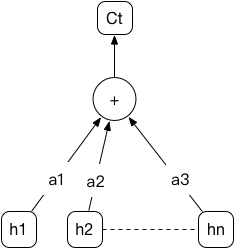
上图就是Attention模型中语义编码Ct的示意图,h是序列中向量的隐含状态,a是由计算得到的权重,分别乘以对应的h后求和就可以得到该序列的语义编码,a数值大的部分代表该部分的向量比较重要。
编码部分就是一个双向的RNN,目前使用GRU的居多,每个向量不再是产生一个隐含状态,而是产生一个由前向和后向的隐含状态的拼接。里面包含着向量的前后联系。
应用
Attention-model主要是在翻译领域应用较多,即解码部分也是一个序列对序列的输出,那么我们怎么用Attention来处理分类任务呢。在情感分析的文章中,有作者是将语义编码视作一个高度概括的向量,然后直接用作分类。但我个人认为用一个单层的GRU来处理下编码信息然后再做分类可能会更完整。总之Attention模型在处理序列的任务中取得了不错的效果,而且其改进的空间也非常大。